森羅2020-ML: 多言語分類タスクに参加しました
はじめに
インターン先の取り組みの1つとして、NTCIR-15のshared taskである森羅2020-ML: 多言語分類タスクに参加し、 12/9〜12/12に行われたNTCIR-15カンファレンスで結果を発表しました。
森羅2020-ML: 多言語分類タスクについて
森羅2020-MLとはWikipediaの知識を計算機が扱える形に構造化することを目指す「森羅プロジェクト」の取り組みの1つで、 多言語のWikipediaページの分類を行うタスクです。
具体的には、カテゴリ分類されたアノテーション済み日本語WikipediaデータとWikipediaページの言語間リンクの情報を用いて、他の言語のWikipediaページをカテゴリ分類するタスクとなります。

提案システム
僕たちのチームは事前学習されたモデルを用いて、マルチクラス分類として今回のタスクを解きました。 具体的には以下で紹介するテキストベースの素性とエンティティベースの素性をWikipediaから取り出し、学習に利用しました。

テキストベースの素性
Wikipediaページのテキストを汎用多言語モデルXLM-RoBERTa1 に入力し [CLS]トークンの位置に対応する最終層の隠れ表現を利用しました。 こちらはBERTベースのテキスト分類ではよく利用される素性となります。
エンティティベースの素性
Wikipediaページに現れるエンティティ群をダンプデータから 直接抽出し、事前学習されたエンティティ表現に変換したものを利用しました。
具体的には、以下の2種類の事前学習済み埋め込み表現を利用しています。
これらのエンティティ表現の集合、すなわちBag of Entityをエンティティベースの素性として利用しました。
提案システムではこれらの素性を連結し、後続のMLP層に入力します。 最終的にはSoftmax Cross Entropyで損失を計算するマルチクラス分類としてタスクを解いています。
さらに提案システムでは以下のような工夫を加えています。
ペアラベルの自動追加
森羅2020-MLタスクは実際には1つのWikipediaページに対して複数のラベルをつけるマルチラベル分類タスクでしたが、 ほとんどの学習データの正解ラベルは1つだったのでマルチクラス分類タスクとして解いています。
実際にマルチラベルを持っているWikipediaページを集計してみると以下の表のように 同じペアで頻繁に共起していることが判明しました。

このことを利用して、ペアでよく共起しているものをペアラベルとして辞書に保持しておき、 推論ラベルに辞書の存在するラベルが含まれれば、相方のラベルもlogitsがある閾値以上であれば推論ラベルに含める というようなヒューリスティックな処理を行っています。 閾値や保持するペアの数は検証データにおける性能で調整しました。
日本語Wikipediaデータによるデータ拡張
基本的には学習データとして、分類済み日本語Wikipediaデータに言語間リンクでつながっている対象言語のWikipediaデータを 利用しています。 しかし、言語間リンクに対応している対象言語のWikipediaデータがないような分類済み日本語Wikipediaデータもあるので これらのデータも学習に利用することでさらなる精度の向上に成功しました。
テキストベースの素性に関しては、マルチリンガルモデルを利用しているので、日本語Wikipediaページのテキストをそのまま入力値として扱いました。 また、エンティティベースの素性に関して、Wikipedia2Vecのエンティティ埋め込み表現は多言語対応しているわけではないので、 エンティティ間の言語間リンクを利用して対象言語のエンティティに変換し、その表現を利用しました。
不均衡データのためのロスの重み付け
正解ラベルに偏りがあり、マイナークラスで精度が出ていないことが判明したので ラベルごとにサンプルの数の平方根の逆数をweightとして設定したCross Entropy Lossで学習しています。 こちらのweightの設定も検証データにおける性能で調整しました。
結果
XLM-RoBERTa baseモデルをベースラインとしてドイツ語で比較実験を行いました。 エンティティベースの素性を加えることでベースラインの性能を上回り、日本語データを利用することでさらなる性能の向上を確認しました。

時間の関係で、ドイツ語にて調整した閾値を用いて他の言語の分類を試みました。 最終提出の結果が以下となります。
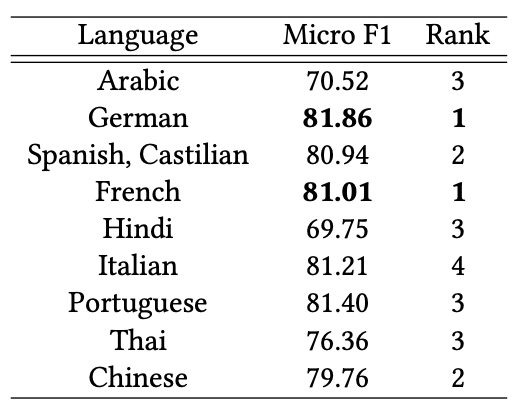
このタスクには10チームほど参加しており、富士通研究所のチームやインド工科大学のチームなども参加していました。 僕たちのチームは提出した9言語中、ドイツ語・フランス語で1位を達成し、他の言語でも高い順位の結果を残すことができました。
おわりに
機械学習系のコンペティションに本格的に取り組んだのは初めての経験で、新たな発見が多々ありました。 特に、データを眺めたり、色んなパターンを試したりと泥臭く性能の向上を追っていくような取り組みは 意外と楽しいということに気付いたのは大きな発見だったと思います。